Lessons Learned from 2 months of ChatGPT in a Mature Product
This is post two in our series Lessons Learned from Adding ChatGPT to a Mature Product. Read post one here.
Two months ago we released the first version of Mito AI. Since then we’ve made two primary improvements. We introduced the Mito AI server so that users no longer needed to bring their own OpenAI key. And we also turned our wacky Mito AI interface into the chat bot interface that we all know and love… or so we thought.
We’re about to release new AI features again, but before we do, we want to reflect on the lessons we’ve learned between iterations one and three.
Lesson 1: Your AI interface primes how users are going to engage with it.
One of the biggest questions we had when releasing Mito AI was whether users were going to continue operating transformation by transformation or if they were going to ask Mito AI to perform more complex tasks.
An individual transformation might be: Convert column A to uppercase
A more complex task might be: Find the percent difference between the age group with the highest average salary and the lowest average salary
Of 150 randomly selected Mito AI users, only four wrote a prompt with more than 250 characters, and the average prompt was only 61 characters. More to the point, only 10% of the Mito AI prompts asked the AI to perform multi-step operations.
We don't think that users are purposefully avoiding asking Mito AI to perform more complex tasks. Instead, we think when and how users turn to Mito AI within their data science workflow shapes how they use it.
- Users are greeted with a single line input field and single line example prompts.
- Individual operations is how you interact with a spreadsheet
- If you’re already using Mito to import data, there’s no friction to editing that data with Mito AI. That’s different from using ChatGPT, where you’ll have to open a new browser, generate code, and copy it back over to Jupyter. Less friction means you use Mito AI more frequently and for smaller tasks that might otherwise not be worth doing in ChatGPT.
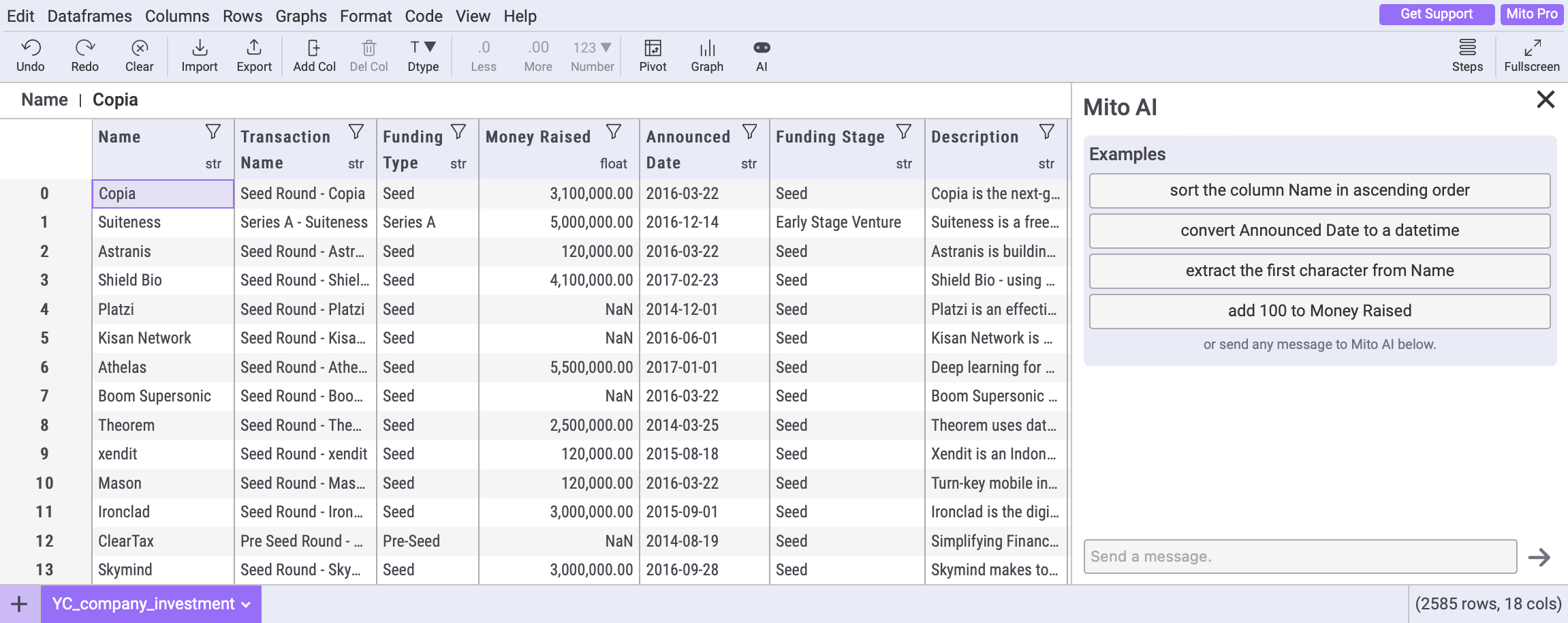
Every company in the world is adding AI to their product. They’re all using the same LLM. And for the most part, they’re all using chat interfaces too. So the context around your AI solution is important.
Lesson 2: The chat history needs to be persistent.
In the first version of Mito AI, your chat history disappeared each time you reloaded the Mito spreadsheet. We heard (and saw) from users that this felt like losing their work.
Similarly to how users often reopen the pivot table taskpane, users also want to reopen their Mito AI chat. Sometimes they wanted to continue the conversation to make additional transformations, and other times they wanted to copy prompts from one Mito spreadsheet to another.
Users take the time to iterate and refine their prompts, and since Mito users are often non-technical, it's the prompt that they want to save as the artifact to reuse, not the generated code.
Lesson 3: Users care about the privacy of their data. Sending information to OpenAI blocks adoption.
Usually, Mito logs no information about your data — no dataframe names, column headers, anything. But of course, in order to use ChatGPT (the model that Mito AI uses under the hood), we need to send API calls to OpenAI.
And in order for the code that OpenAI generates to be useful, we supplement the user input with additional context about your analysis — things like the names and column headers of your dataframes.
So the first thing that a new Mito AI users sees is an updated privacy policy that explains all ^ in a bit more detail. Only 47% of people that open Mito AI accept the updated privacy policy. We clearly explain that info gets sent to OpenAI, and 53% of our users are clearly tell us "No thanks”.
Even more, many enterprises have completely blocked access to OpenAI. For security concious users, its important to offer solutions that give them control over their data. Mito Enterprise users can connect Mito AI to an On-Prem LLM instead of sending data to OpenAI.
Lesson 4: Chat interfaces are the most intuitive way to interact with AI, but they still have a learning curve.
Mito AI’s original interface was, excuse my language, garbage. We over engineered it because we wanted to give users as much control as possible. For example, you could edit the AI generated response in place. Users don’t need that much control when texting, and they don’t need that much control when talking to an LLM.
Moving to the OpenAI-inspired chat interface reduces a lot of the friction our initial design introduced.
If you’ve used ChatGPT before then you’ll be able to start using Mito AI to transform your data right away. On the other hand, if you haven’t used ChatGPT before, you’ll have to get your head around this new interface for generating code.
This was a surprise to us. We thought that everyone would pick up how to use the Mito AI chat interface right away. But to the contraray, we watched more than one user who thought that the three example prompts we provided were the only things they could use Mito AI for, not realizing they could add any prompt they wanted in the chat input field.
Lesson 5: Chat Interfaces are not enough. Users need tools to understand the impact of the AI generated code on their data.
Jupyter notebooks are so much better than main.py style data exploration because they minimize the steps needed to iterate your analysis. Make an edit, see the effect, and make another edit. Doing that loop as quickly as possible is the name of the game.
Chat interfaces are quickly becoming the fastest way to edit your data, but they still aren’t, and maybe never will be, the best tool for understanding the effect of the edit on your data. That’s what spreadsheets are great at!
In the newest release of Mito AI, we focussed on closing the loop between making a transformation with Mito AI and using the spreadsheet to understand the effects of the generated code on your data.
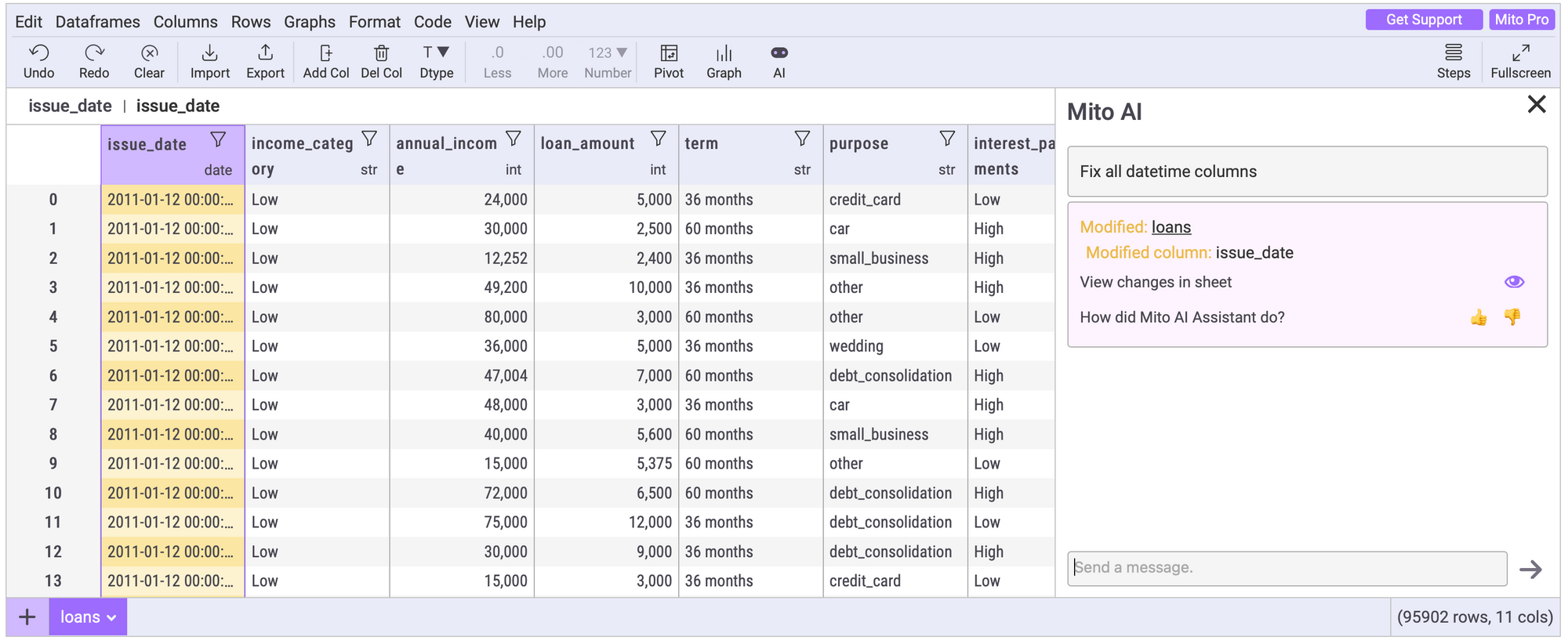
That’s what the next release of Mito is focussed on – closing the loop between making a transformation with Mito AI, and using the spreadsheet to understand the effects of the generated code on your data.